[5분 로봇] Against Appearance Changes 3
on 5min-Robot
U. Toronto에서 공개한 RA-L논문이다. 기존의 How to train a cat이란 논문으로 appearance change 상황에서 visual localization 성능을 높이는 연구를 진행했었는데, 이 논문도 마찬가지로 낮-밤과 같이 다른 환경에서 visual localization 성능을 높이는 방향에 대해서 연구하였다.
Learning Matchable Image Transformations for Long-term Metric Visual Localization
재밌는 것은, 옥스포드나 ETH와 같은 경우에는 image translation이 원래 training domain에 포함되는 도메인 인데 (예를들면, 밤 → 낮, 낮→밤과 같이), Toronto 대학에서는 robust canonical image를 찾는 것을 목적으로 한다. 즉, 매칭이 잘되는 특정 형태의 이미지로 변환하는 것이다. (옥스포드도 이전에는 illumination invariant imaging이라고 해서 모델 기반으로 비슷한 연구를 진행하였다.)
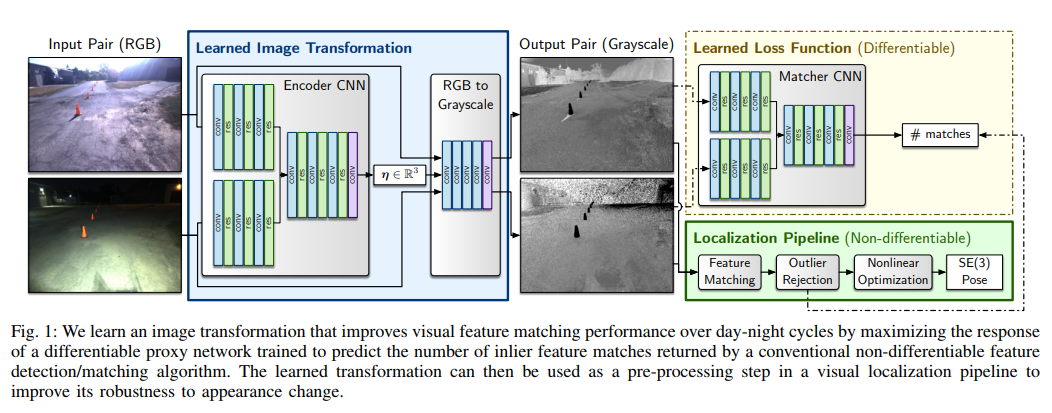
아직 이 논문을 제대로 읽지 않아서 명확하게 설명하긴 어렵지만, 위 그림으로 구성을 쉽게 파악할 수 있다. 주목할만한 부분은 2가지 인데,
- Enc-Dec 구조로 이미지를 [HxWx3] → [HxWx3] 형태로 변환하는 것이 아니라, RGBtoGray 변환하는 것 처럼 RGB 각 채널에 대한 fusion 파라미터를 학습한다. 즉, I = xR + yG + zB에서 x, y, z를 학습하는 것이다. → 변환에 의한 왜곡이나 디테일 손실없이 영상 변환이 가능하다.
- 결국 matching 결과가 좋아지도록 학습해야 하는 것인데, 기존의 localization pipeline에서 획득할 수 있는 inlier-outlier 정의를 이용해서 학습을 진행할 수 있다.
좀 더 자세히 보기위해서는 코드 및 논문을 읽어보아야 하겠지만, 이 논문에서 주목할만한 포인트는 단순히 visual localization 성능을 끌어올린 것보다도 기존 모델 기반 방법을 딥러닝에 얼마나 잘 적용했느냐 일 것이다.